Transformer 出处
论文地址:https://arxiv.org/abs/1706.03762
Transformer 特点
讲这个算法呢首先我觉得应该了解到他的优点和解决的问题,为什么有了CNN和RNN等类型的网络Transformer还会火起来,他解决了两个问题:
- 与CNN相比他能捕获长距离特征
- RNN也可以捕获长距离特征,但是RNN捕获是通过把当前词嵌入与之前的词嵌入向量通过神经元节点激活值结合,也就是前一时刻的计算,无法做到并行,而Transformer使用的是self-attention不会出现这种时间上的依赖,可以做到并行。
Transformer 详细过程
假设我们把他用作机器翻译上从高层视角来看,我们喂给Transformer以一种语言,Transformer输出翻译结果
那么我们一层层的将这个Transformer黑盒展开,展开第一层我们可以看到他有两个模块组成编码组件与解码组件部分
我们继续展开编码组件与解码组件部分,一系列的编码器(论文中是6个)和解码器组成了编码组件和解码组件
那么编码器又由self-attention和前馈神经网络构成,每个编码器结构相同,但不共享权重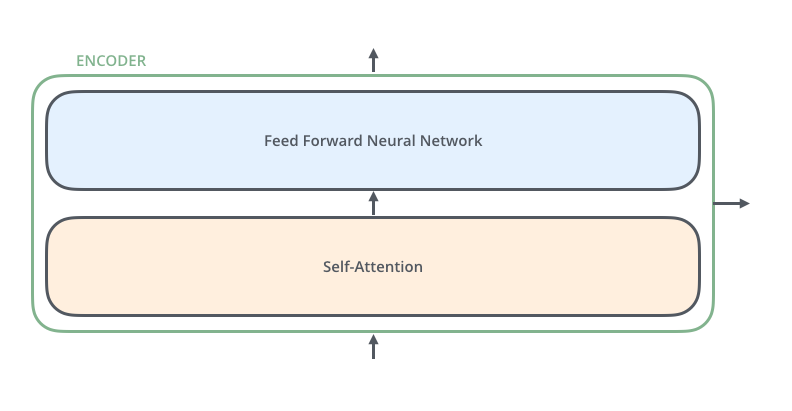
我们的输入(通常为词嵌入向量)首先经过self-attention层,这一层可以计算出其它输入词对当前输入词关关系度的权值,接着输入到前馈神经网络,解码器除了包含这两个结构外还多了一个encode docode attention部分,用来关注输入句子的相关部分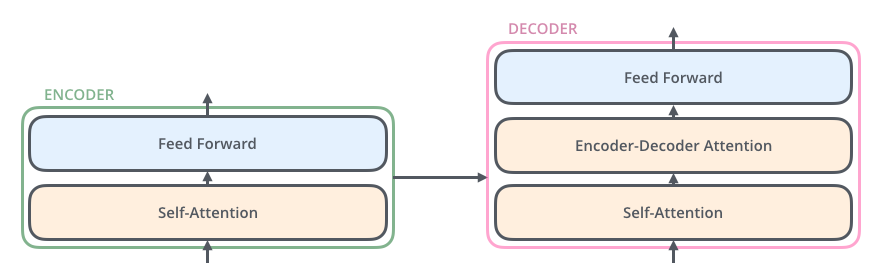
结合数据演示模型工作流程
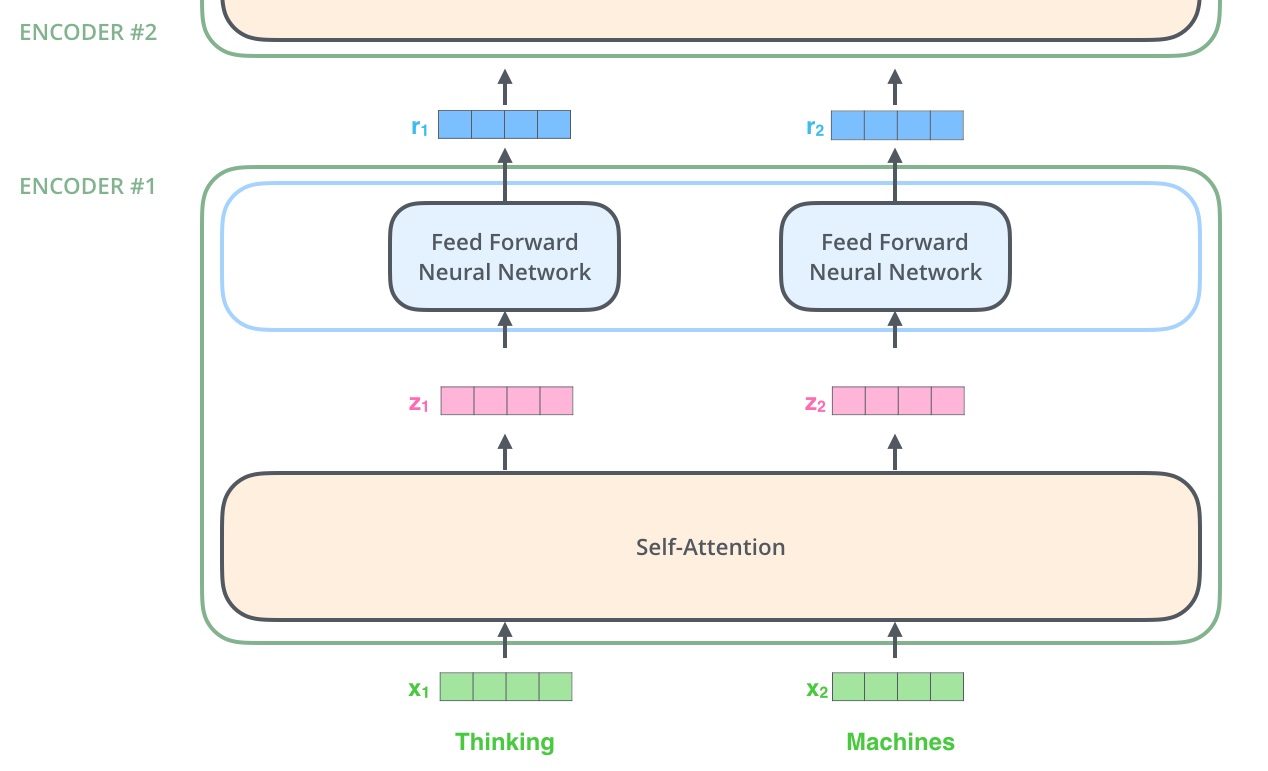
首先我们将待翻译的句子用ebedding方法向量化,每个词表示为一个长度为512维的向量,简略的用下图四个格子代表这512维的向量
模型的最底层输入是词嵌入经过编码器中的两层结构输出,底层编码器的输出结果作为上层编码器的输入
Self-Attention
假设有待翻译的句子
1 | The animal didn't cross the street because it was too tired |
那句子中的it是指animal还是指street,我们很好区分it是指animal但是算法做起来却很困难,self-attention的做法是在编码it时我们同事关注句子中的其他词,这样就能更好的对it进行编码。
RNN是之前已经处理过的词的激活值与当前词向量结合作为隐层输入来保持与前文词的关联关系的,self-attention将所有词共同关联到当前词这种方式保存关联关系![]()
Self-Attention详细过程
根据输入的当前词我们获取这个词的三个向量、query查询向量、key键向量、value值向量,后续简称为q、k、v,这三个向量是通过512维词向量与训练的权值矩阵相乘得到的,qkv三个维度相同(文章中小于512为64这取决于权值矩阵的维度)![]()
当我们输入当前词为thinking时,我们就需要考察其他单词也就是tingking本身和matchines,在对thinking编码时所要投入的“关注度”(权值),也就是其它词对当前词进行打分,打分通过当前词的查询向量$q_1$与其它词的k进行点乘也就是$q_1k_1$ 与$q_1k_2$![]()
接着我们将点乘的结果除以8(这里选取k的维度64的开方,为了有稳定的梯度),接着做softmax操作,将他们按比例和变为1![]()
softmax值代表着每个词对当前词thinking编码贡献分数。
solfmax值与v向量相乘,强化相关单词(solfmax值大的)并弱化不相关单词(softmax值小的)。
接着将加权值v向量进行求和作为self-attention当前词的输出![]()
到这里self-attention的计算结束了,后续把输出送到前馈神经网络中,实际中并不是这样每个词向量逐个计算的是通过矩阵乘法进行的。
Self-Attention矩阵运算
计算查询矩阵Q键矩阵K值矩阵V,分别用输入词向量矩阵X与训练权值矩阵$W^Q W^K W^V$相乘得出![]()
接着做Q与K矩阵乘法除以K的维度开方(论文中为8)后做softmax后与V相乘![]()
self-attention矩阵计算完成
multi-headed attention
通过multi-headed attention后可以进一步的提高attention层的性能,主要以下两个方面
- 经过self attention后$z_1$有句子中其他部分都能在$z_1$编码中有所体现,但是这种还是有可能被实际的当前词所支配,对于“The animal didn’t cross the street because it was too tired”,要知道it所指的是那个词,multi-headed attention可以起到作用
- 通过随机初始化化多个不同的$W_q,W_k,W_v$可以将其映射到不同的子空间,让模型多角度理解输入子序列,多attention组合优于单个attention

如果我们用self-attention计算过程处理那么将产生多个不同的Z矩阵,前馈网络中只需要一个这样的Z矩阵,我们将$Z_1…Z_8$(原文中8个)进行拼接后乘以变换矩阵$W^0$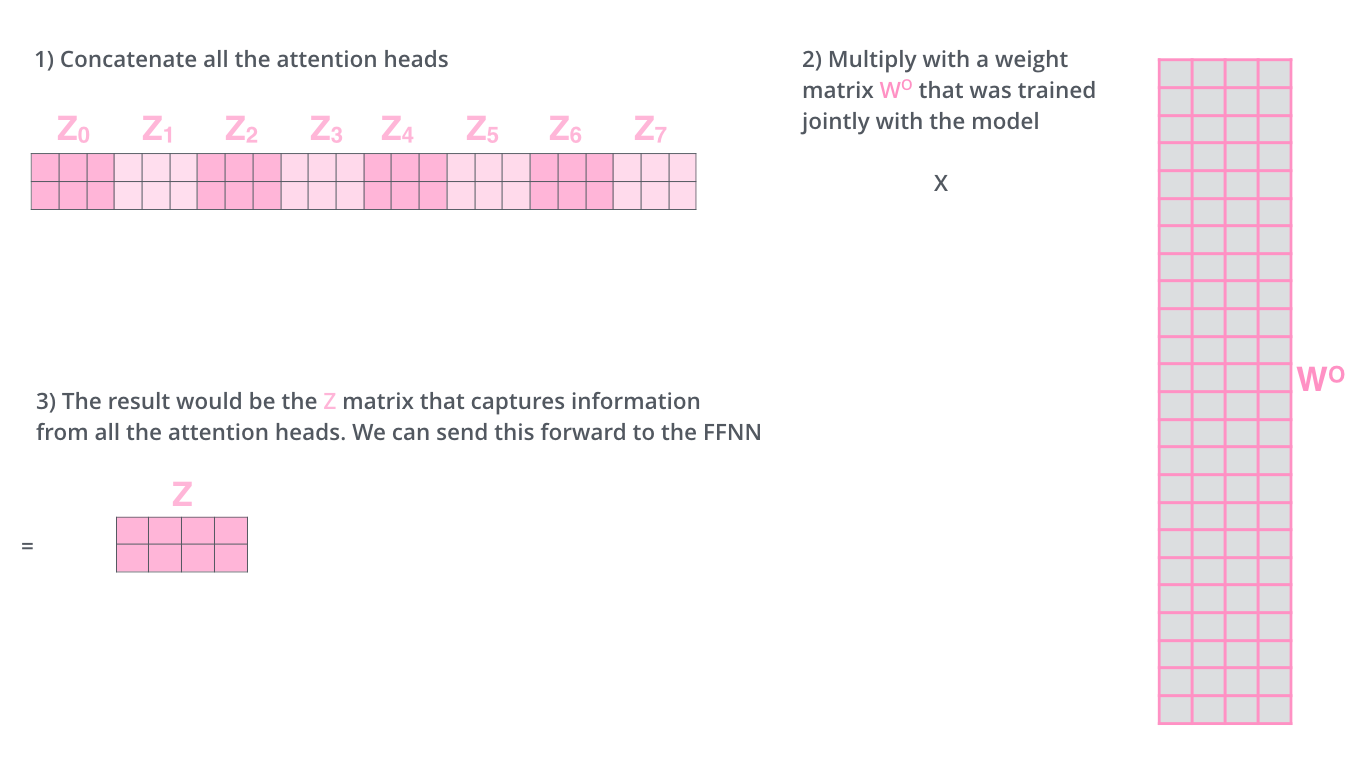
整个multi-headed attention计算过程
使用位置编码
加入位置向量,将词嵌入向量与位置向量结合形成词向量能更好的表达词与词之间的距离![]()
假设每个词嵌入维度为4,下午代表位置向量与词嵌入的结合![]()
残差模块
编码器每个子模块之间(self-attention、前馈神经网络、下一层编码器)都有一个残差连接,进行层归一化操作![]()
可视化层归一化操作![]()
解码器与编码器相似,下图是2个编码器解码器的transformer结构![]()
解码器
最后一个编码器出去Z后也会形成K、V向量,将K、V向量送入解码器
完成编码后进行解码工作,解码每个步骤都会输出一个序列,翻译中每个步骤都会数据部分翻译结果,重复这个过程直到遇到终止符号。