TextRNN出处
论文出处: Recurrent Neural Network for Text Classification with Multi-Task Learning
TextRNN原理
在自然语言处理中,我们的语言序列往往不是孤立的,比如说词性预测,动词后面往往大概率是跟随的是名词,跟随动词的几率会很小,RNN可以很好的处理带有序列的问题,并具有短时记忆能力。
RNN的主要改变是将上一次的激活值a,输入到下次时间步骤中参与计算,下一时刻的计算不仅要考虑输入数据x也要使用上一时刻的激活值a。
计算公式:
$a^t = g_1(W_{aa}a^{t-1} + W_{ax}x + b_a) $
$y^t = g_2(W_{ya}a^t + b_y)$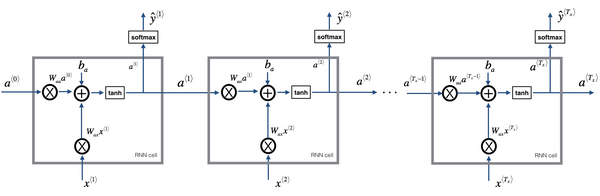
RRN之LSTM算法
LSTM可以解决长序列的梯度消失和爆炸问题,LSTM通过门控制单元,可以学习很深的连接,LSTM有着长短时记忆的能力,通过遗忘门、更新门、输出门控制。
LSTM的引入了记忆细胞它的数据包含了记忆细胞c与上一适合的激活值a还有数据数据输入x,主要包括三个阶段:
- 遗忘阶段。对上次层传来的输入进行选择性遗忘,忘记不重要的,记住重要的,主要通过遗忘门控制$c^{t-1}$
- 记忆阶段。通过更新门选择记忆重要的信息
- 输出阶段。通过输出门控制

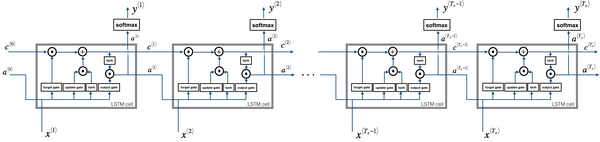
当输入上一层的记忆信息$c^{t-1}$时我希望有一个门$Γ^t_f=\sigma(W_{fa}a^{t-1} + W_{fx}x^t + b_f)$能控制是否遗忘和保留引入,本级网络也会根据输入$x^t$与$a^{t-1}$计算出产生的信息$\hat{c}^t = tanh(W_{ca}a_t-1 + W_{cx}x^t + b_c)$,我们使用更新门$Γ^t_u=\sigma(W_{ua}a^{t-1} + W_{ux}x^t + b_u)$更新经过本层后的需要记忆的记忆细胞值$c^t = Γ^t_f\circ c^{t-1} + Γ^t_u\circ \hat{c}^t$,使用输出门$Γ^o = \sigma(W_{oa}a^{t-1} + W_{ox}x^t + b_o)$对记忆细胞进行变换为下一层的输入$a^t=Γ^t\circ tanh(c^t)$TextRNN模型结构
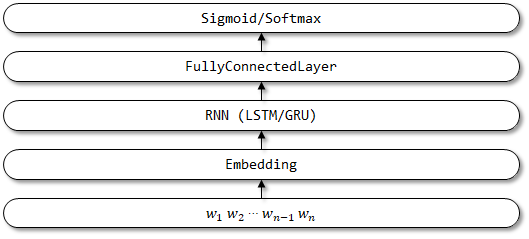
基于TensorFlow 2.x实现TextRNN模型
1 | from tensorflow.keras import Input, Model |