当我们训练完一个模型算法后,我们该如何评估模型算法是好是坏呢?在模型评估过程中,往往需要根据具体场景使用不同的指标进行评估,在诸多的评价指标中,大部分指标只能片面的反应模型的一部分性能,如果不能合理的运用评估指标,则可能会得出错误的结论。
数据集类别
我们通常将数据分为三类:训练集、验证集、测试集。
- 训练集:主要在训练阶段使用用于学习模型参数。
- 验证集:测试模型在新数据上的表现,同时通过调整超参数,让模型处于最好的状态。
- 测试集:检验模型的能力
模型评估是通过测试集进行评估,我们会得到一些最终的评估指标,例如:准确率、精确率、召回率、F1等。
评估方法
- 留出法:将数据集划分为两个互斥的部分,其中一部分作为训练集,另一部分用作测试集
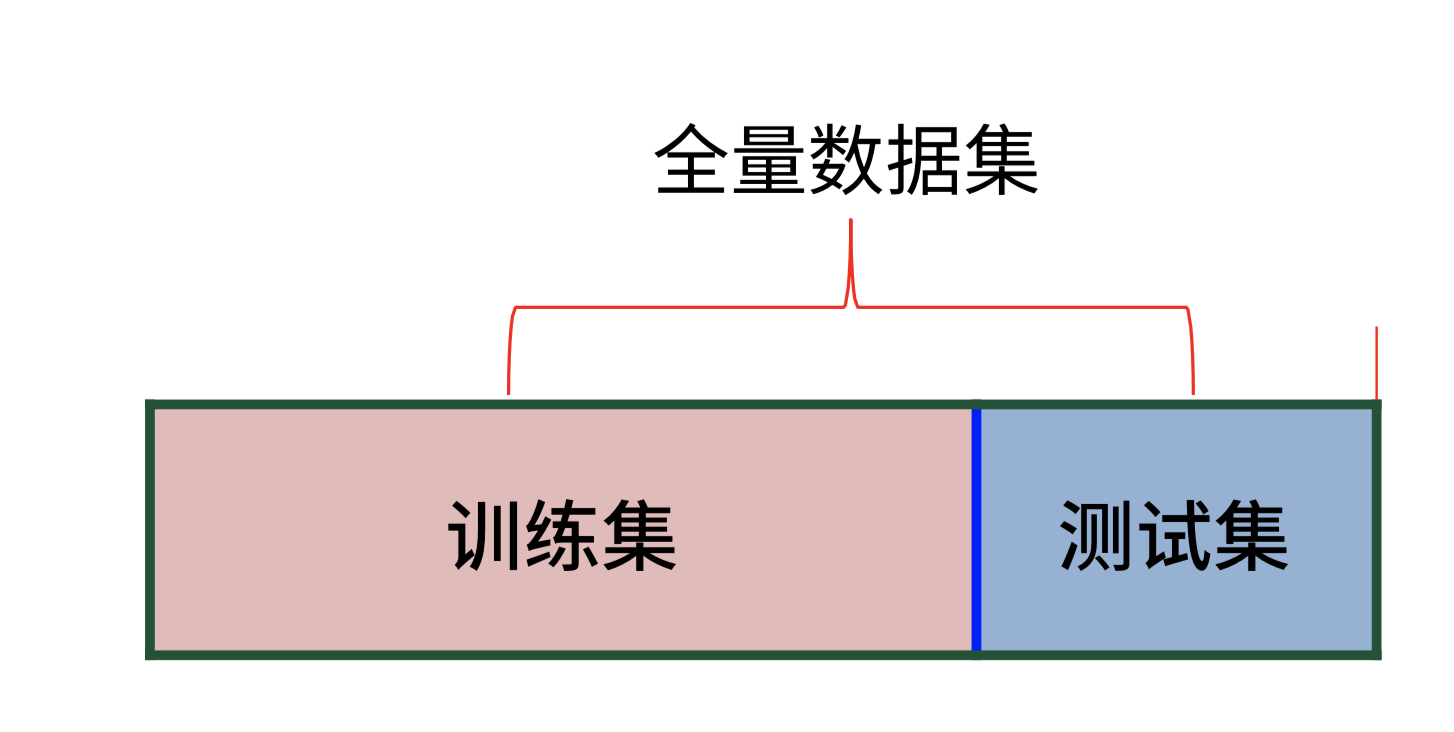
- 注意点:
- 保持数据分布一致(使用分层采样)
- 多次重复划分(如采用10次随机划分)
- 测试集不能太大或者太小(一般使用30%)
- 交叉验证法:将数据集划分为k个的互斥子集,每次采用k-1个子集的并集作为训练集,剩下的那个子集作为测试集
10折交叉验证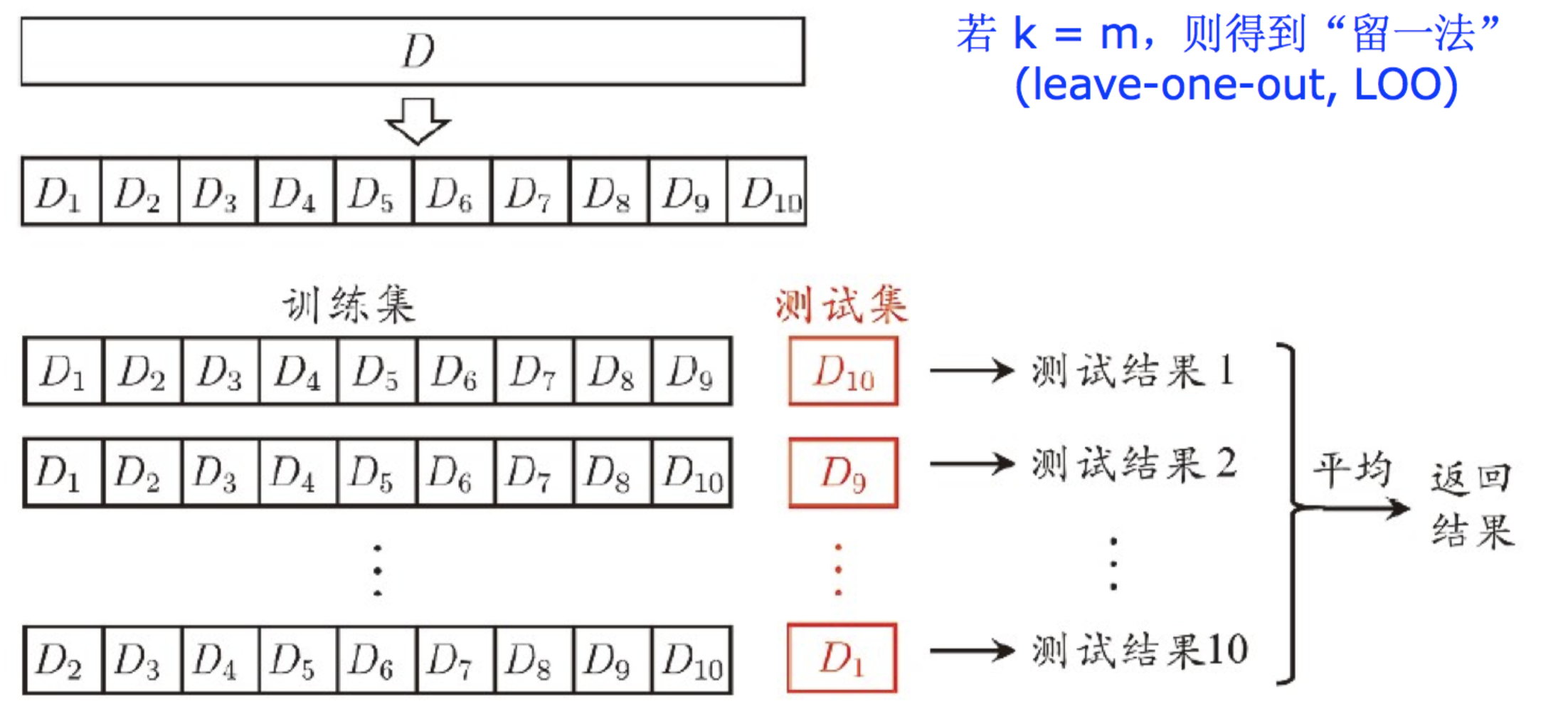
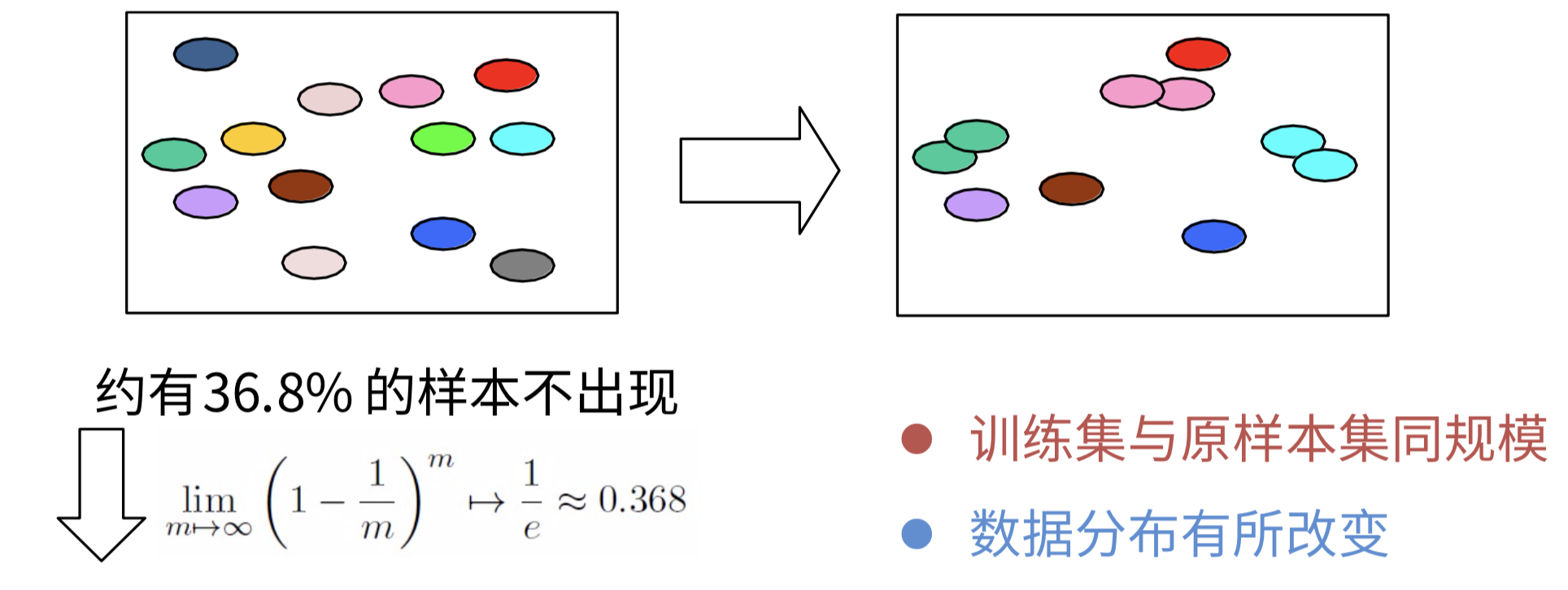
- 自助法:每次随机从数据集中挑选一个样本,记录到训练集,然后将样本放回n次之后,得到n个样本的训练数据集。剩余未采样到的数据为测试集
分类问题评估指标
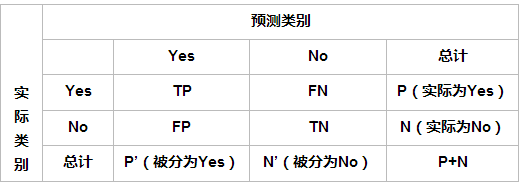
在二分类问题中,假设该样本一共有两种类别:Positive和Negative。当分类器预测结束,我们可以绘制出混淆矩阵(confusion matrix)。其中分类结果分为如下几种:
| head | Positive | Negative |
|---|---|---|
| Positive | TP(真正例) | FN(假反例) |
| Negative | FP(假正例) | TN(真反例) |
- True Positive(TP):预测为正例,实际为正例,即算法预测正确(True)
- False Positive(FP):预测为正例,实际为负例,即算法预测错误(False)
- True Negative(TN):预测为负例,实际为负例,即算法预测正确(True)
- False Negative(FN):预测为负例,实际为正例,即算法预测错误(False)
由此引入Accuracy、Precision、Recall、F1-Score等等评估指标:
Accuracy:准确率,指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例,反映的是模型算法整体性能,其公式如下:
$Accuracy = \frac{TP + TN}{TP + TN + FP + FN}$- 分类正确的个数占总数的百分比,不适合样本不均衡场景,如癌细胞检测,欺诈检测。
Precision:精确率,指的是正确预测的正样本数占所有预测为正样本的数量的比值,也就是说所有预测为正样本的样本中有多少是真正的正样本,它只关注正样本,这是区别于Accuracy的地方,其公式如下:
$Precision = \frac{TP}{TP + FP}$- 判定正例中真正正例的个数与判定为正例的比例
Recall:召回率,指的是正确预测的正样本数占真实正样本总数的比值,也就是指能从这些预测样本中能够正确找出多少个正样本,其公式如下:
$Recall = \frac{TP}{TP + FN}$
$Recall = \frac{TP}{TP + FN}$- 判定为正例中真正正例的个数与总正例的比例
F1-Score:精确率与召回率的平均调和,计算公式如下:
$F1\text{-}score = \frac{2\times \text{Precision} \times \text{Recall}}{ \text{Precision}+\text{Recall}}$AUC(Area UnderCurve):AUC就是ROC曲线下的面积,因为ROC“随机猜测”模型通常对应于其对角线,因而通常AUC的值范围为0.5~1,其值越大说明模型算法的性能越好,AUC为0.5时模型算法为“随机猜测”,其值为1时说明模型算法达到理想状态。
PRC(Precision-RecallCurve):精准率-召回率曲线也叫PR曲线,其以Recall为X轴坐标,以Precision为Y轴坐标,通过对模型算法设定不同的阈值会得到不同的precision和recall值,将这些序列绘制到直角坐标系上就得到了PR曲线,PR曲线下的面积为1时则说明模型算法性能最为理想。
混淆矩阵:多分类混淆矩阵,在混淆矩阵中,正确的分类样本(Actual label = Predictedlabel)分布在左上到右下的对角线上。其中,Accuracy的定义为分类正确(对角线上)的样本数与总样本数的比值。Accuracy度量的是全局样本预测情况。而对于Precision和Recall而言,每个类都需要单独计算其Precision和Recall。
使用sklearn求解评价指标
计算准确率、精确率、召回率代码
1
2
3
4
5
6
7
8
9
10
11
12
13from sklearn import metrics
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.metrics import accuracy_score
#分类结果
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 1, 1]
print("accuracy_score:", accuracy_score(y_true, y_pred))
print("precision_score:", metrics.precision_score(y_true, y_pred))
print("recall_score:", metrics.recall_score(y_true, y_pred))
print("f1_score:", metrics.f1_score(y_true, y_pred))
print("f0.5_score:", metrics.fbeta_score(y_true, y_pred, beta=0.5))
print("f2_score:", metrics.fbeta_score(y_true, y_pred, beta=2.0))sklearn ROC 和 AUC 的实现
1 | from sklearn import metrics |
- 绘制PR曲线代码
1 |
|